


Some of my work











Projects

Unified Data Access with Multi-Database Integration
Integrated diverse databases (Apache Spark, MongoDB, HBase, Cassandra, Redis, Kafka, Neo4j) using Apache Drill for SQL-based querying, improving data access and management efficiency. Published on Docker and GitHub.
GitHub
Legal Contract Q&A Bot
Developed a Retrieval Augmented Generation (RAG) system for legal contract Q&A using LangChain, OpenAI models, and ChromaDB for effective information retrieval.
GitHub
Supply Chain Analysis Using Spark
Analyzed a dataset of 180,000 rows and 53 columns of supply chain-related information using PySpark to assess the risk of late deliveries and suggest optimizations in the supply chain.
GitHub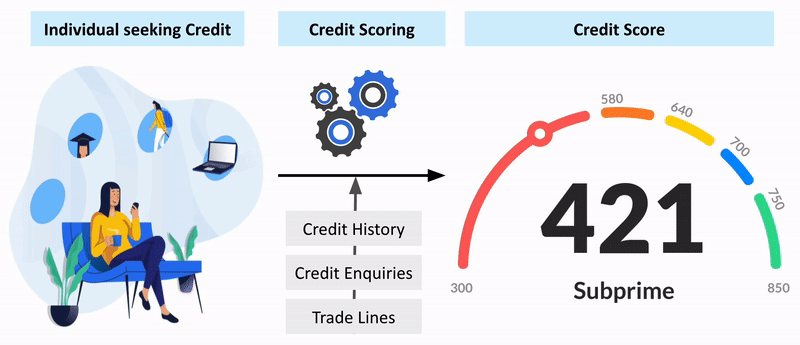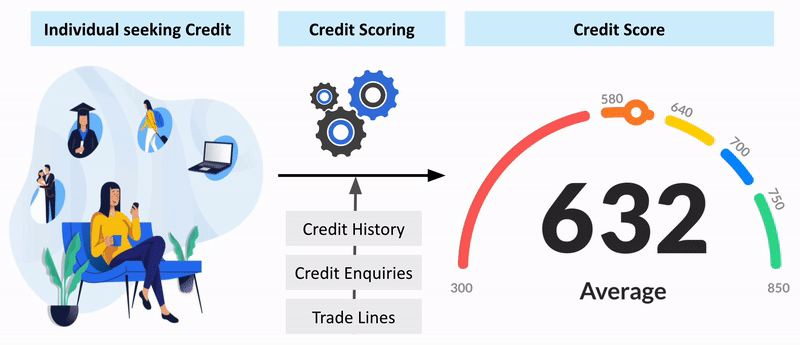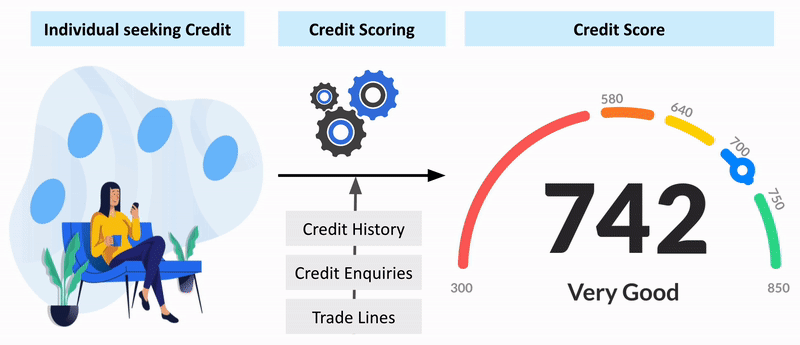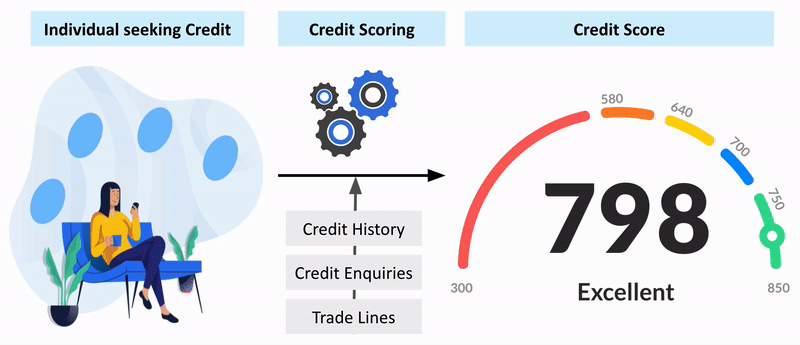
Credit Risk Analysis with Machine Learning
Applied machine learning for credit risk analysis, focusing on loan default prediction. Shared findings and methodologies to aid in understanding predictive models.
GitHub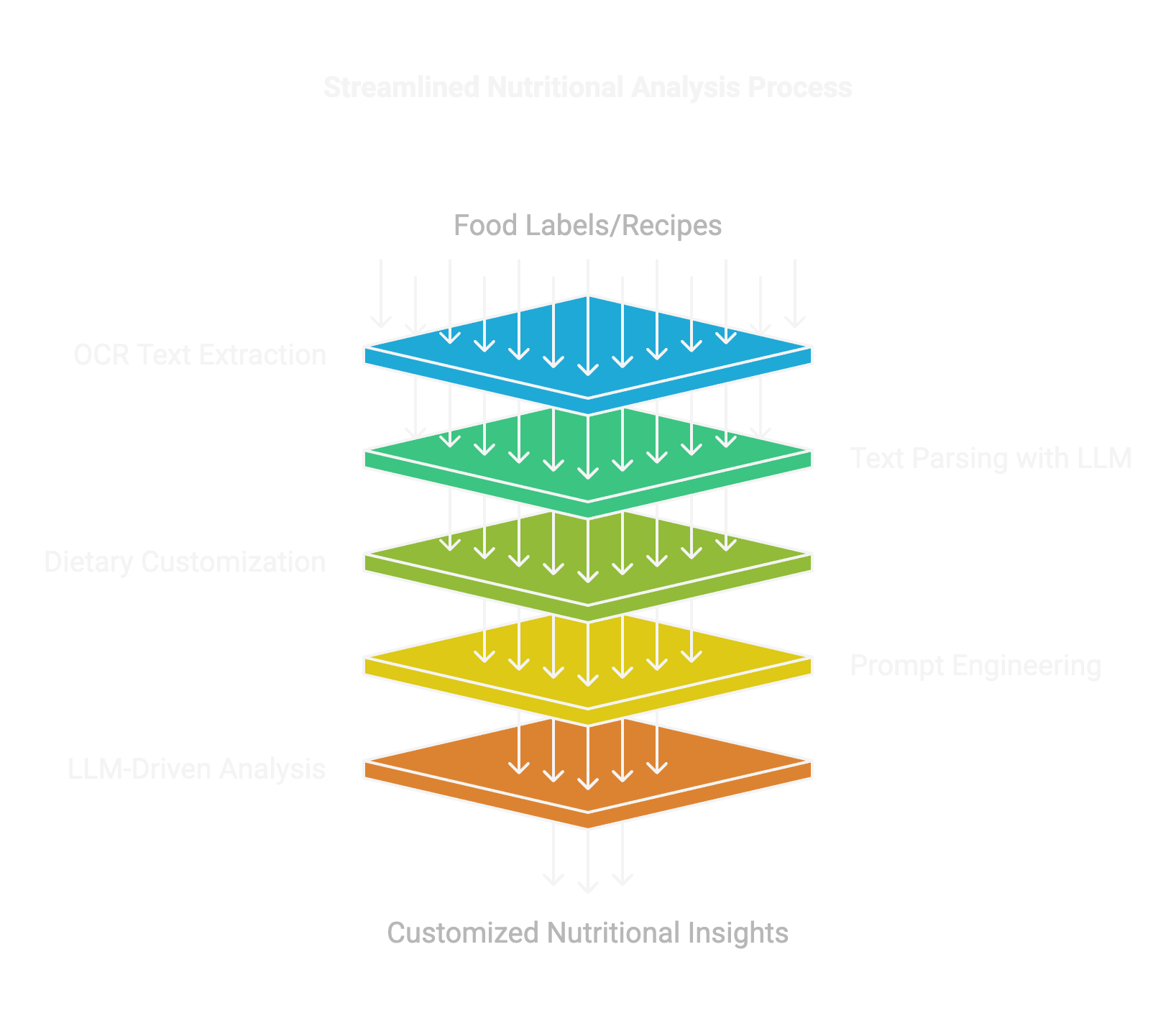
Nutrient Analysis from Food Label Images Using Data-Driven Models
AI-powered tool that automates extraction and analysis of nutritional information from food labels using OCR, NLP, and LLMs. Provides accurate, personalized dietary insights tailored to user preferences, simplifying health management and empowering informed food choices.
GitHubIntroducing `Prabs`

I am a data engineer and analyst with a strong foundation in data science and over five years of experience in analytics, data engineering, and client service.
My name is Prabin Raj Shrestha, and I also go by Prabs
Holding a Master’s in Applied Data Science from Syracuse University, where I specialized in database management, business analytics, and natural language processing, I bring a technical and analytical approach to problem-solving. Additionally, my undergraduate degree in Mechanical Engineering has given me a solid grounding in quantitative analysis and operational efficiency.
Most of my days are spent diving deep into datasets, scripting, and engineering data pipelines.
My core skills span data analysis, data engineering, machine learning, and visualization, with a focus on creating end-to-end data solutions. I enjoy tackling complex data challenges, from building scalable data infrastructures to analyzing patterns that can reveal hidden insights.
Working on projects that start with gathering data from multiple sources and end with actionable insights—like identifying student retention patterns or improving credit risk assessment—fuels my drive to make a difference through data.
In my free time, I like to work on personal projects that explore my interests in emerging data technologies and machine learning. I enjoy contributing to the data science community by creating tutorials and sharing code on platforms like GitHub. Whether it’s building starter kits for data visualization or offering guidance on data engineering,
I believe in giving back by sharing knowledge with others who are just as passionate about data as I am.
I have learned much of what I know through a mix of hands-on experience, formal education, and online resources, from Coursera courses to open-source projects.
I am grateful to the online educators and data science communities that have made learning accessible and engaging. To pay it forward, I publish project walkthroughs and tutorials to help others navigate the world of data science and engineering.
Feel free to explore my projects and repositories, where you’ll find code that’s open for you to use, adapt, or simply gain inspiration from. My goal is to keep pushing boundaries in data science and share insights that might spark the same excitement in others that I feel every time I start a new project.